Mathieu Escouteloup
mardi 13 janvier 2026
Architecture des processeurs 4: Pipeline
Les capacités de calcul (ou performances) d’un processeur sont généralement la principale caractéristique à prendre en compte lors de la conception. Comme pour tout système numérique, l’une des solutions pour augmenter le débit de calculs réalisés est d’augmenter la fréquence d’horloge. Pour cela, un mécanisme essentiel est alors implémenté : le pipeline.
Sur cette page, nous allons étudier le fonctionnement d’un pipeline dans un processeur. Notamment, nous verrons comment il impacte l’exécution des programmes. Également, nous étudierons les différents aléas susceptibles de pénaliser le débit final.
riscv-sim avec Visual Studio Code.
Dans le terminal de l’IDE, configurez l’environnement du simulateur puis placez-vous dans le répertoire sw/uarch/pipe.Analyse d’une simulation
Pour les différentes simulations, nous aurons besoin de considérer de nouveaux signaux afin de voir l’évolution de l’exécution.
Dans GtkWave, ceux-ci sont regroupés par étage dans Pipeline : IF0 pour Instruction Fetch 0, IF1 pour Instruction Fetch 1, etc.
Également, vous retrouverez imem et dmem, respectivement les signaux des ports mémoire d’instructions et de données.
Dans une implémentation réelle de processeur avec un pipeline, des signaux internes sont associés au PC et à l’instruction dans chaque étage pour effectuer l’exécution.
Notamment, un signal essentiel est le signal indiquant la validité (ici valid) des informations présentes dans un étage.
Deux cas sont alors possibles :
- Le signal
validest à1: cela signifie qu’une instruction est en cours d’exécution dans l’étage correspondant. - Le signal
validest à0: cela signifie qu’aucune instruction n’est en cours d’exécution dans l’étage correspondant. Cela correspond à une bulle dans le pipeline. Les autres signaux de l’étage, quelle que soit leur valeur, peuvent être ignorés.
Pour illustrer ce fonctionnement, on va considérer une instruction addi t0, zero, 1 située à l’adresse 0x08000028.
L’objectif va être de suivre son exécution au sein du pipeline.
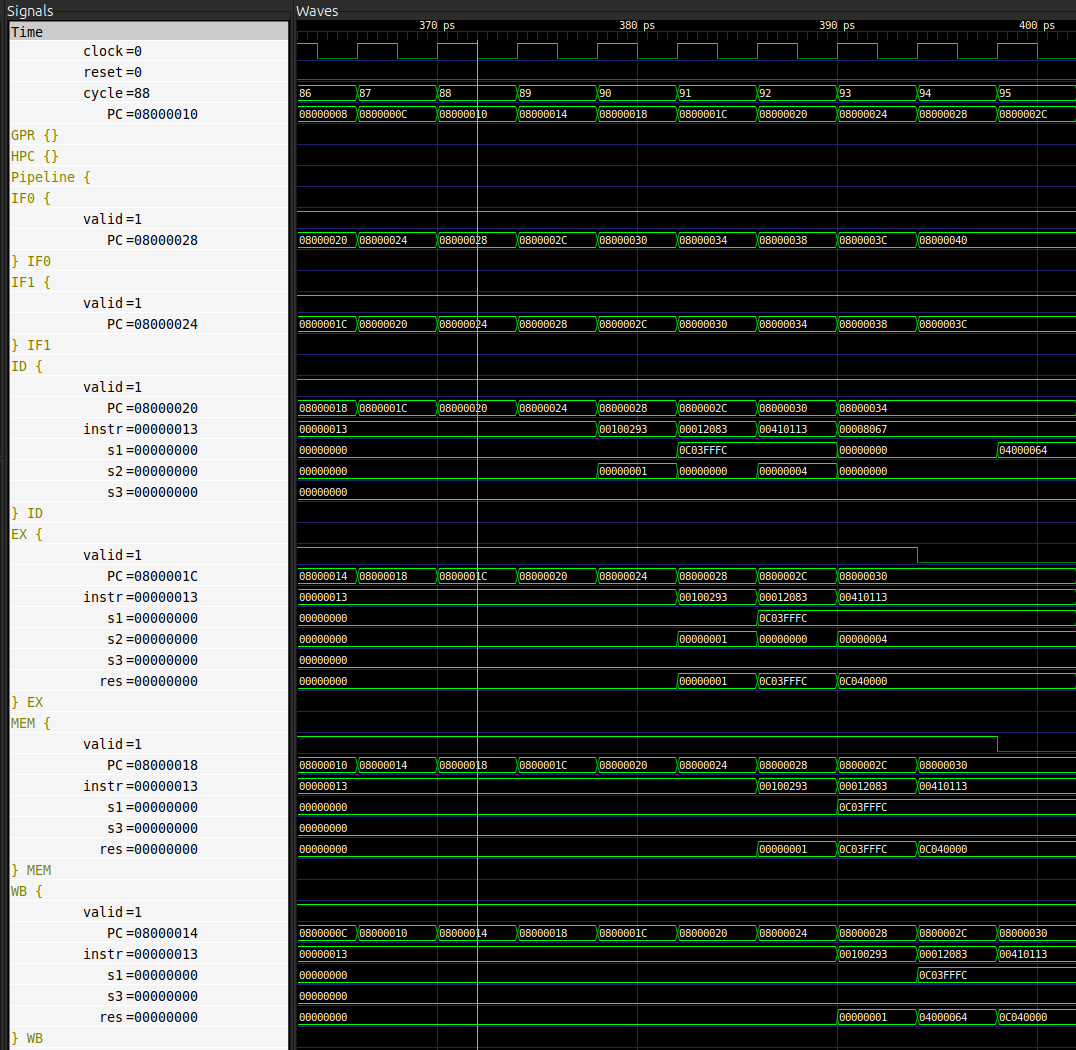
Tout d’abord, on se place au niveau du premier étage, ici IF0.
À l’aide du signal PC dans cet étage, l’objectif est de repérer quand l’instruction entre dans le processeur pour commencer son exécution.
Ainsi, dans le cas de la figure ci-dessus, on constate que PC = 0x08000028 au cycle 88.
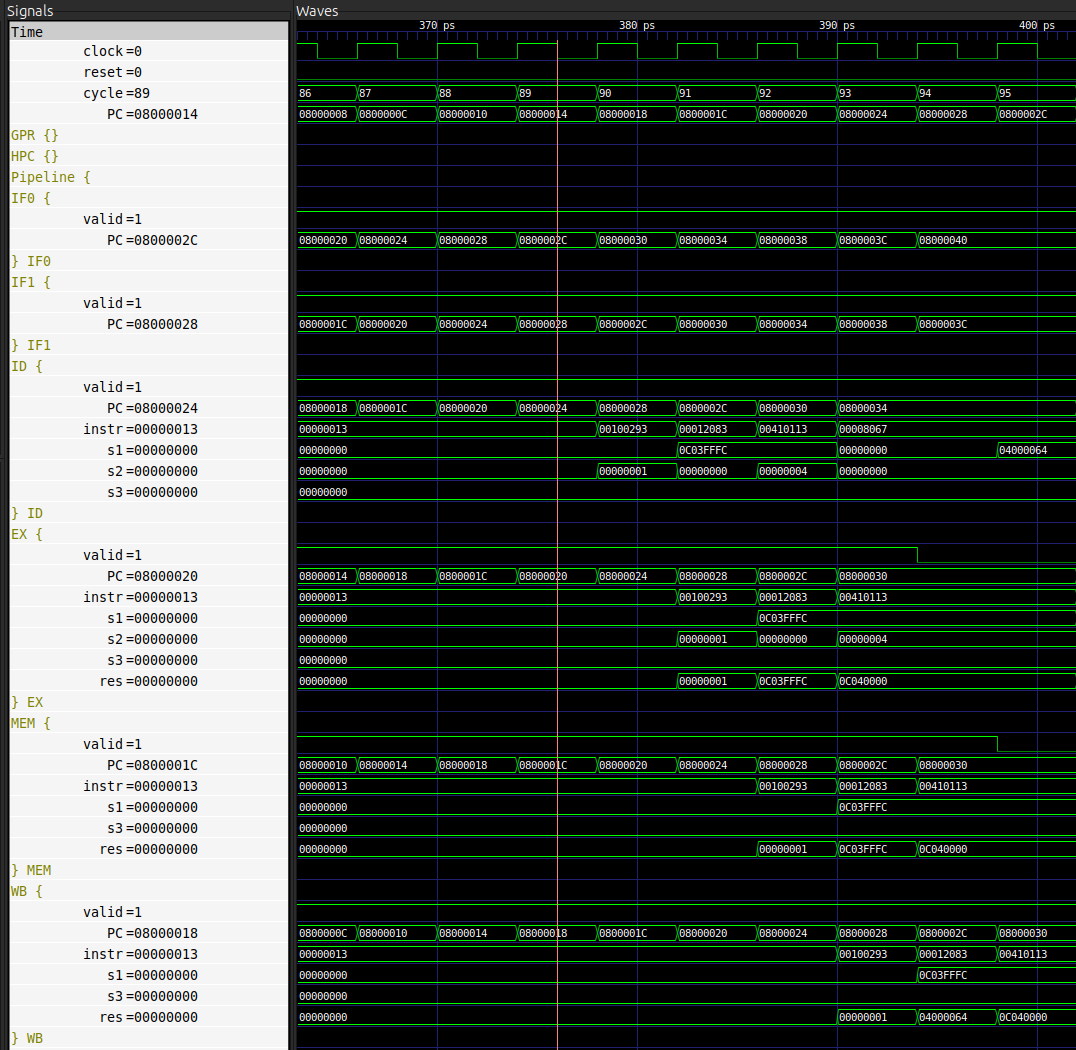
Dans le cas sans aléa, l’instruction progresse d’un étage au cycle suivant.
Ainsi, sur la figure ci-dessus, on constate que PC = 0x08000028 au cycle 89 dans l’étage IF1.
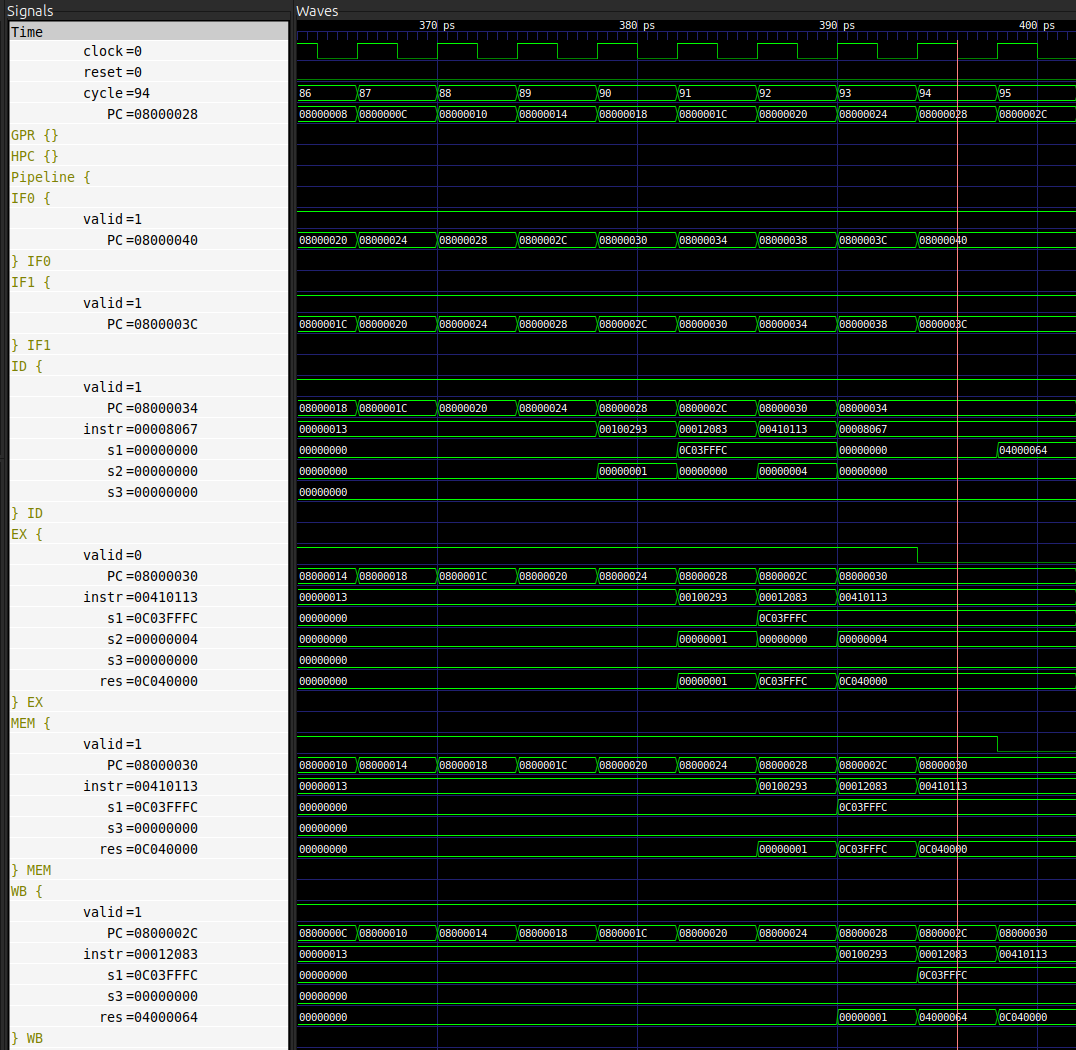
Durant les cycles suivants, l’instruction progresse d’étage en étage.
Finalement, une instruction est considérée comme entièrement exécutée lorsque le PC global contient son adresse.
Ici, on constate sur la figure ci-dessus que PC = 0x08000028 au cycle 94 : 94 - 88 = 6 cycles auront donc été nécessaires pour exécuter entièrement l’instruction addi t0, zero, 1.
Étude d’un pipeline

Pour comprendre l’impact des choix d’implémentation, une stratégie est de comparer l’exécution d’un même programme sur deux microarchitectures différentes.
Ainsi, pour l’ensemble des simulations, nous exécuterons nos programmes sur deux processeurs différents: core_0 et core_1.
Ces deux processeurs sont issus d’un même design configurable dont la microarchitecture est décrite sur la figure ci-dessus.
La plupart des étages du pipeline, les unités d’exécution ou autres mécanismes peuvent être activés / désactivés au moment de la conception.
Il est donc possible de générer des microarchitectures aux caractéristiques différentes à partir d’une même base de code RTL.
Par le biais des différentes simulations, l’enjeu de cette partie sera de retrouver certaines des caractéristiques de core_0 et core_1.
make exec et make view permettent de choisir le processeur ciblé à l’aide du paramètre CORE_NAME.
Par exemple, make exec CORE_NAME=core_0 et make view CORE_NAME=core_0 exécutent le programme et visualisent le chronogramme généré par core_0.Pipeline, on constate que deux étages IF0 et IF1 sont utilisés.
Expliquez leur utilité dans le cas où la mémoire contenant les instructions est dite synchrone.Dans le fichier main.S, ajoutez la suite d’instructions suivantes:
nopnopnopnopnopnopnopnopaddi t0, zero, 2
main.S, effectuez une multiplication entre la valeur 0x10 et la valeur 0x20 que vous rangerez ensuite dans le registre t3.
À partir de quel étage / cycle le résultat est-il calculé ?
À partir de combien de cycles est-il disponible dans un registre pour être réutilisé ?Aide supplémentaire (si nécessaire)
L’instruction RISC-V pour la multiplication prend la forme mul rd, rs1, rs2.
main.S, récupérez dans t1 la valeur de 32 bits située en mémoire à l’adresse 0x10018000.
À partir de quel étage / cycle le résultat est-il récupéré ?
À partir de combien de cycles est-il disponible dans un registre pour être réutilisé ?main.S, mettez dans t2 la valeur 0x000000ab et rangez-la à l’adresse 0x10018008.
À partir de quel étage / cycle le résultat est-il rangé ?
À partir de combien de cycles l’instruction est-elle complètement exécutée ?
Vous pouvez observer le résultat dans la partie SCRATCH_REG du chronogramme.Aléas de structure
Du point de vue implémentation, toutes les opérations ne sont pas équivalentes en temps et en complexité. Par exemple, des opérations comme la multiplication ou la division peuvent s’avérer coûteuses à réaliser en nombre de portes logiques mais aussi en nombre de cycles d’exécution. On parle alors d’instructions multi-cycles pour des instructions demandant plusieurs cycles d’horloge afin d’être réalisées. Lorsque ce phénomène intervient, une instruction peut donc rester bloquée au sein d’un étage du pipeline. Chaque étage ne pouvant contenir qu’une instruction à la fois, les instructions qui suivent doivent également être bloquées : on parle alors d’aléa de structure. Dans cette partie, on se propose d’analyser l’impact d’une instruction de multiplication ou de division sur l’exécution globale, et de voir comment les aléas de structure peuvent être gérés du point de vue du matériel.
Tout d’abord, on va considérer le cas de la multiplication.
Pour cela, dans le fichier main.S, ajoutez la suite d’instructions suivante:
li t0, 0x22li t1, 0x3mul t2, t0, t1nop
nop sur les deux processeurs core_0 et core_1.
Que constatez-vous ?MULDIV du processeur.
À partir du schéma précédent, que peut-on déduire de la structure interne de cette unité dans les deux processeurs core_0 et core_1.Dans le fichier main.S, ajoutez à présent la suite d’instructions suivante:
li t4, 0x87654321li t5, 0x1div t6, t4, t5nop
nop sur les deux processeurs core_0 et core_1.
Que constatez-vous ?Aléas de données
Problématique
Les différentes instructions d’un programme ne sont pas complètement indépendantes. Des instructions proches sont généralement susceptibles de manipuler un même registre.
Dans un processeur implémentant un pipeline, les étapes de lecture des registres et d’écriture du résultat peuvent être séparées de plusieurs cycles. Ainsi, si une instruction a besoin du résultat d’une instruction précédente, elle devra attendre que cette dernière soit terminée afin de pouvoir utiliser son résultat: on parle alors de dépendance (ou aléa) de données. Dans cette partie, nous allons analyser l’impact des dépendances de données sur l’exécution globale, et voir comment le compilateur et/ou le matériel peuvent être adaptés pour gérer ces cas.
main.S, mettez en place une dépendance de données entre deux instructions arithmétiques et logiques.
À partir du chronogramme et de la partie Étude d’un pipeline, détaillez à quel moment (étage) la dépendance est détectée et jusqu’à quand la seconde instruction est bloquée.core_0 et core_1, que peut-on conclure de l’impact de la taille du pipeline sur le temps d’exécution ?On souhaite à présent étudier le pseudo-code suivant:
d0 <- 4d1 <- MEM[0x10018000]d2 <- d1 + d0d3 <- (d1 << 2)d4 <- d2 + d3MEM[0x10018008] <- d4d5 <- MEM[0x10018004]d6 <- d5d7 <- d6 + d1d8 <- d7 + d4MEM[0x1001800c] <- d8d9 <- d4 AND 1
dX doit être remplacé par un registre RISC-V de votre choix.
Essayez d’utiliser le moins de registres possibles.Gestion en compilation
Lorsque l’on utilise un langage de programmation de plus haut niveau que le langage d’assemblage tel que le C, le compilateur peut jouer un rôle majeur sur la gestion des aléas. Lors de la compilation, l’outil dispose de la plupart des informations nécessaires :
- La liste des données manipulées,
- La liste des registres disponibles,
- Les liens entre celles-ci,
- Les opérations à effectuer. Ainsi, en supposant qu’il possède des informations supplémentaires sur le processeur ciblé (latence des instructions, présence de mécanismes de bypass, etc.), il peut tout à fait adapter le code généré. Dans notre cas, on peut simplifier les optimisations en quatre phases distinctes:
- Suppression / Simplification des opérations (e.g. utiliser directement les opérations avec immédiat),
- Identification des dépendances de données entre les opérations (ordre strict des opérations à respecter),
- Nommage / renommage des registres (e.g. réduction des différentes dépendances entre les instructions),
- Réorganisation des opérations selon le processeur ciblé (e.g. exécution en priorité des instructions dont dépendent d’autres opérations).
Gestion matérielle
L’impact du compilateur reste limité en fonction des opérations à réaliser et des données manipulées. Par exemple, dans le cas où toutes les instructions sont inter-dépendantes, son impact pourra s’avérer nul: aucune instruction ne pourra être déplacée. Ainsi, les optimisations matérielles ont alors un rôle essentiel pour diminuer les pertes dues aux aléas de données. Notamment, une stratégie efficace est l’implémentation d’un réseau de bypass / renvoi des données (data forwarding). L’idée majeure est alors de rendre disponibles à la lecture les résultats dès qu’ils sont calculés, sans attendre qu’ils soient écrits dans les registres de destination. Il est alors possible dans de nombreux cas de réduire l’introduction de bulles dans le pipeline.
core_0 et core_1, décrivez une implémentation idéale pour chaque processeur d’un réseau de bypass.main.S, ajoutez juste avant la macro UARCH_OPT1_EN.
Mesurez à nouveau le temps d’exécution de la suite d’instructions.
Que constatez-vous ?Aide supplémentaire (si nécessaire)
La macro UARCH_OPT1_EN insère des instructions directement dans le programme.
Ainsi, pour évaluer l’impact sur le temps d’exécution, ne considérez que votre suite d’instructions, dont les adresses peuvent changer.
Aléas de contrôle
Problématique
L’exécution d’un programme ne concerne pas forcément une suite linéaire d’instructions. Ainsi, certaines d’entre elles permettent de rediriger le flot de contrôle à des adresses différentes. Dans le cas de l’architecture RISC-V, deux types d’instructions de redirection existent: les sauts et les branchements conditionnels.
Du point de vue d’un pipeline, ces redirections sont pénalisantes afin de conserver un débit d’exécution élevé. Généralement, les opérations de redirection sont calculées un ou plusieurs cycles après l’opération de récupération de l’instruction. Dans certains cas, il devient alors nécessaire de vider le pipeline (flush) afin d’effacer les mauvaises instructions récupérées avant de réorienter l’exécution.
call et ret.
Après avoir créé une fonction func_loop n’effectuant aucun calcul, évaluez le coût d’un appel de fonction et d’un retour au niveau du temps d’exécution d’un programme.On souhaite à présent étudier le pseudo-code suivant au sein de la fonction func_loop:
r0 <- a0r1 <- a1r2 <- a2for (r3 = 0; r3 < r2; r3 = r3 + 1)r0 <- r0 + r1a0 <- r0
Gestion en compilation
Tout comme pour la gestion des aléas de données, le compilateur peut influencer le code généré afin de limiter l’impact des redirections. Deux stratégies par exemple peuvent se faire au détriment de la longueur du code:
- Le déroulage de boucle consiste à dupliquer le contenu d’une boucle autant de fois que nécessaire. Les instructions générées peuvent alors s’exécuter de manière linéaire.
- L’extension inline (ou inlining) consiste en le remplacement d’un appel de fonction par le corps de la fonction. En plus de supprimer les instructions d’appel et de retour, cela permet également de simplifier le passage des arguments.
a2 est fixé à 5, évaluez l’impact des différentes stratégies.Gestion matérielle
Au sein de la microarchitecture, il est également possible d’intégrer des mécanismes afin de limiter l’impact des redirections du flot d’exécution. La stratégie utilisée est généralement la même: anticiper autant que possible les redirections afin de limiter le surcoût.
func_loop à l’exception de l’instruction de retour.
Dans main.S, effectuez deux appels successifs à la fonction, séparés par 10 nop.
Avant le premier appel, ajoutez la macro UARCH_OPT2_EN.
Que constatez-vous ?