Mathieu Escouteloup
mardi 13 janvier 2026
Architecture des processeurs 6: Mémoire cache
Le processeur ne correspond qu’à la partie opérationnelle du système. Ainsi, pour avoir un système pleinement fonctionnel, il est également nécessaire de l’associer à une ou plusieurs mémoires afin de stocker les différentes instructions et données. Généralement, ces composants sont bien plus lents que le processeur lui-même, ce qui peut impacter les performances de l’ensemble du système.
Sur cette page, nous allon étudier le fonctionnement des mémoires caches, des mémoires intermédiaires permettant de réduire les limitations de la mémoire principale. À l’aide de simulations, nous verrons comment les temps d’accès peuvent varier selon les opérations effectuées. Nous verrons également l’impact du placement des données en mémoire, par exemple lors de la manipulation de tableaux ou matrices.
riscv-sim avec Visual Studio Code.
Dans le terminal de l’IDE, configurez l’environnement du simulateur puis placez-vous dans le répertoire sw/uarch/cache.Analyse en simulation
Pour les différentes analyses des smulations de cette page, nous aurons besoin de retrouver deux types d’informations à partir du chronogramme: le temps d’accès mémoire (utile pour distinguer un hit d’un miss) et l’état d’une ligne de cache.
Temps d’accès mémoire
Afin de mesurer le temps nécessaire pour effectuer un accès mémoire depuis le processeur, le plus simple est de se placer au niveau des ports mémoires (instruction et / ou donnée). Cela permet de s’abstraire de la plupart des autres mécanismes de la microarchitcture pouvant influencer nos mesures. En se plaçant à cet endroit-là, on peut précisément détecter quand une demande est effectuée à la mémoire, et quand la réponse correspondante est reçue.
Sur le chronogramme, vous trouvez les signaux des ports mémoires dans Pipeline, esprectement dans imem et dmem.
À l’intérieur, vous trouverez plusieurs groupes de signaux:
reqles signaux pour l’envoi d’une demande du processeur vers la mémoire.writeles signaux pour l’envoi d’une donnée à écrire du processeur vers la mémoire.readles signaux pour la réception d’une donnée lue de la mémoire vers le processeur.
Chaque groupe de signaux est organisé autour d’une transaction en poignée de main (handshake).
Pour cela, deux signaux sont toujours présents: valid indique si un envoi est en cours par l’émetteur et ready indique si le récepteur est prêt à la recevoir.
Un échange n’est validé que quand les deux signaux sont simultanément à 1 en fin de cycle.
Sinon, il est nécessaire de patienter au moins un cycle supplémentaire.
Nous allons ici prendre le cas d’un accès mémoire pour une donnée (port dmem) en lecture réalisé à l’adresse 0x0c000304.
Pour connaître le temps d’accès réel, il va donc falloir mesurer la différence de temps (cycles) entre le moment où la requêtes a été acceptée (groupe de signaux req) et le moment où la réponse a été reçue (groupe de signaux read).
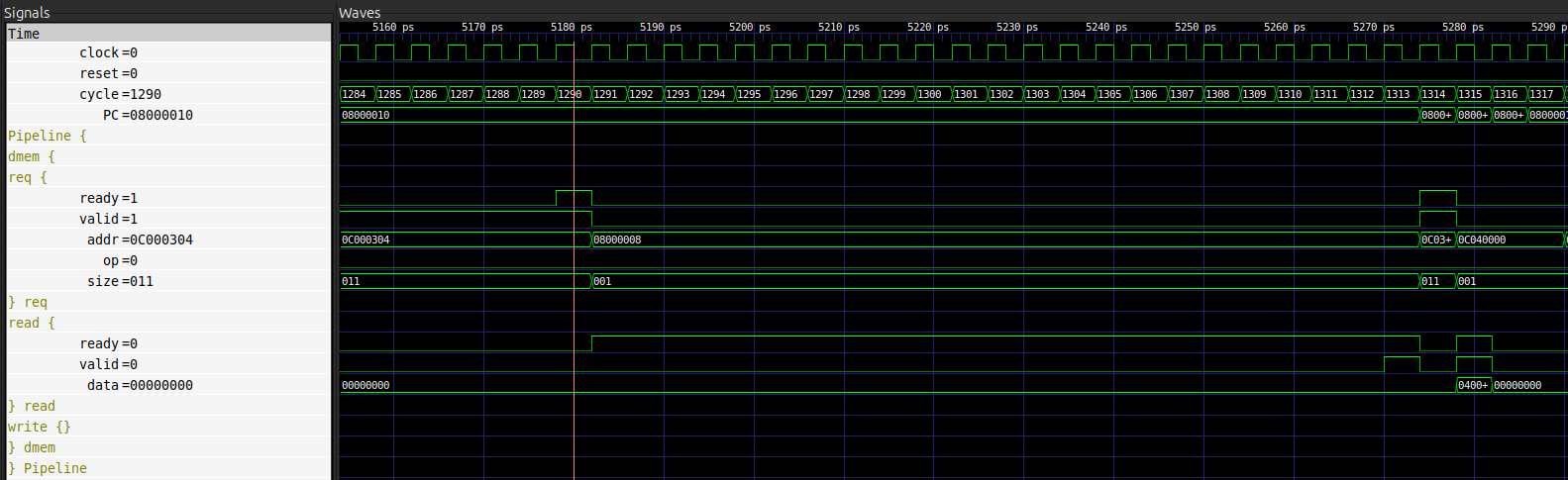
Sur l’image ci-dessus, le curseur indique le moment où la requête à l’adresse 0x0c000304 est envoyée par le processeur (valid = 1) et acceptée par la mémoire cache (ready = 1).
Le chronogramme nous indique également que cette opération a lieu au cycle 1290.
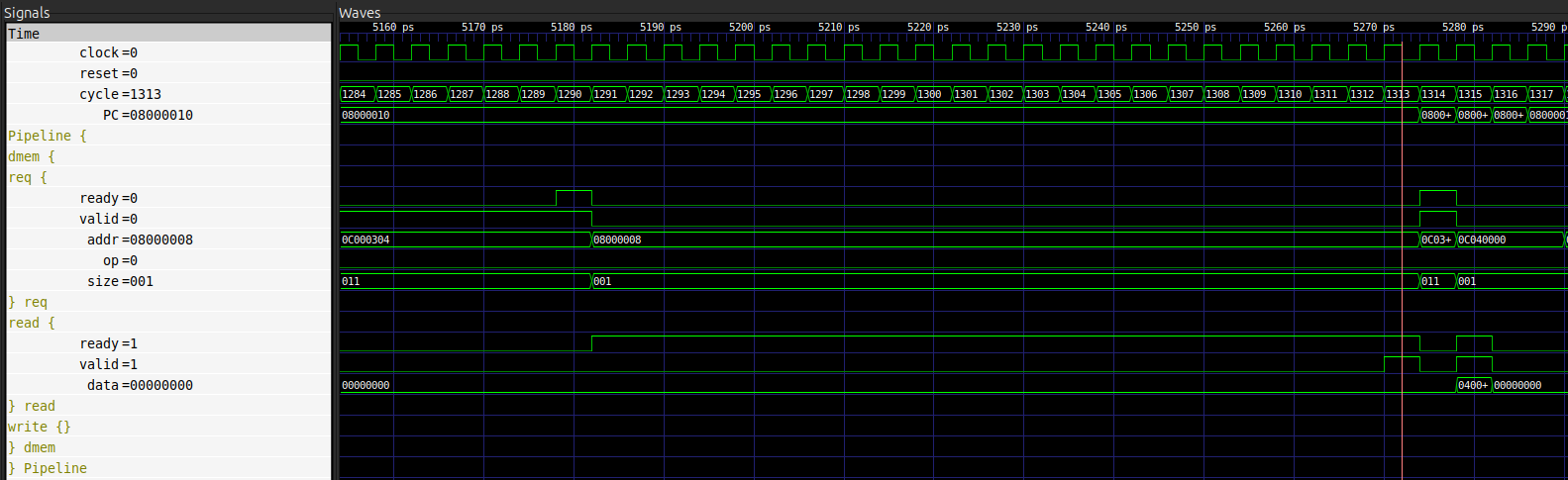
Cette requête étant une deamnde de lecture, la réponse correspondante sera ici la prochaine donnée reçue par les signauc read.
Sur cette nouvelle image, le curseur indique maintenant le moment où la réponse est envoyée par la mémoire (valid = 1) et acceptée par le processeur (ready = 1).
Le chronogramme nous indique également que cette opération a lieu au cycle 1313.
Au final, le temps d’accès mémoire a ici duré $1313 - 1290 = 23$ cycles. En sachant qu’un hit devrait mener à un accès d’un seul cycle (aucun ralentissement), on peut donc supposer ici que l’on observe un cache miss.
État d’une ligne de cache
Pour analyser le contenu d’une mémoire cache à un instant donné, il peut être nécessaire de vérifier l’état d’une ligne.
Pour cela, le chronogramme rassemble les signaux de chaque ligne en groupe (par exemple Line 0), eux-mêmes rassemblés par sous-ensemble (par exemple set 0) au sein de chaque mémoire cache (par exemple L1D).
L’image suivante représente l’évolution des différents signaux pour une seule ligne.
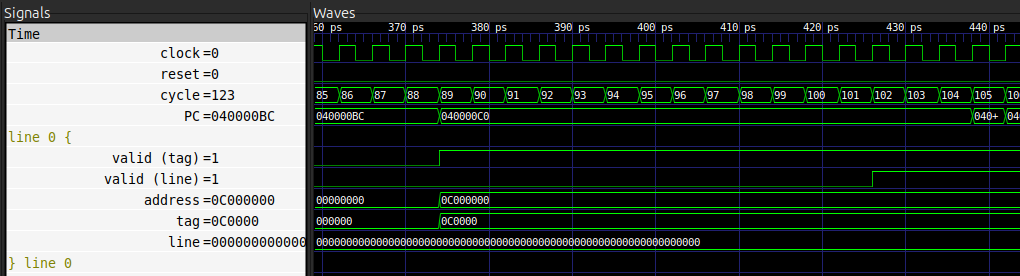
Ces signaux étant propres à l’implémentation simulée. Voici leurs significations:
valid (tag)indique la validité du tag stocké actuellement. Si le signal est à1, alors l’emplacement est occupé et le tag est valide. Sinon, l’emplacement est libre. Ce bit est particulièrement utile pour indiquer si une ligne est présente ou non.valid (line)indique la validité du contenu de la ligne. Si le signal est à1, alors le contenu est valide. Sinon, le contenu n’est pas disponible. Ce bit est particulièrement utile pour indiquer que le contenu n’est pas encore prêt, par exemple quand il est en train d’être chargé.tagindique le tag de la ligne correspondante.lineindique le contenu de la ligne entière.addressindique l’adresse de base de la ligne entière (valeur du tag + numéro du sous-ensemble + décalage à0). Ce signal n’est présent qu’en simulation pour le debogage: il n’existe pas réellement dans l’implémentation car il serait inutile: le signal detagsuffit.
À partir de ces informations et du chronogramme précédent, on peut donc analyser l’état de ligne ainsi:
- Avant le cycle
89,valid (tag)est à0: cela signifie que l’emplacement est libre car aucune ligne n’y est stockée. - Au cycle
89,valid (tag)passe à1: l’emplacement vient d’être alloué pour la ligne ayant le tag0x0c0000(soit l’adresse0x0c000000ici). - Jusqu’au cycle
102,valid (line)reste à0: cela signifie que les opérations pour charger la ligne depuis le niveau de mémoire supérieur sont toujours en cours. - À partir du cycle
102,valid (line)est à1: le contenu de la ligne est donc valide et disponible dansline.
Accès mémoire
Pour les différentes simulations réalisées sur cette page, nous allons à présent utiliser le langage C. L’intérêt majeur va être de faciliter l’utilisation de structure mémoire telles que des tableaux ou des matrices. Nous allons voir comment le compilateur traduit cela en opérations en langage d’assemblage.
func dans func.c, réalisez une lecture de la variable var et stockez la valeur lue dans une variable temporaire tmp.
Quelle instruction est utilisée ?0 dans var.
Quelle instruction est utilisée ?Initialement, la variable var est déclarée ici avec la ligne volatile uint32_t var;
Le mot-clé volatile permet d’indiquer au compilateur que la variable associée est susceptible dêtre modifiée par un autre programme ou mécanisme matériel.
func avec / sans la variable var déclarée volatile.
Que constatez-vous comme changement ?
Pourquoi ?Pour les simulations qui suivent, on utilisera cette fonctionalité afin de agrantir que les opérations mémoires seront exécutées par le processeur.
Principe de localité
Le rôle d’une mémoire cache est de conserver à l’intérieur des copies de certaines parties de la mémoire principale afin de les rendre plus rapidement accessibles au processeur. Cependant, de par leurs tailles réduites, ces mémoires ne peuvent copier toute la mémoire principale simultanément. Ainsi, lors d’un accès mémoire passant par une mémoire cache, deux scénarios deviennent donc possibles:
- La donnée demandée est présente dans la mémoire cache. Celle-ci peut donc répondre rapidement: c’est ce qu’on appelle un cache hit.
- La donnée demandée n’est pas,présente dans la mémoire cache. Des opérations supplémentaires sont alors nécessaires pour aller récupérer la donnée dans la mémoire principale avant de répondre à la requête initiale: c’est ce qu’on appelle un cache miss.
Le choix des données placées dans la mémoire cache devient donc essentiel dans le but de réduire les temps d’accès. À partir d’observations générales sur l’exécution des programmes, il est cependant possible de déduire certains comportements liés aux accès mémoires effectués. Dans les faits, ceux-ci ne sont pas entièrement aléatoires et donc des anticipations sont possibles. On regroupe ces observations sous le nom de principe de localité, qui peut être déclinée en deux concepts: la localité temporelle et la localité spatiale.
Localité temporelle
Le concept de localité temporelle est l’observation que lorsque qu’une zone mémoire est utilisée, il y a de plus grandes chances qu’elle soit ré-utilisée dans un futur proche. C’est le cas des instructions placées dans des boucles ou fonctions, ou alors des variables elles-mêmes manipulées par plusieurs opérations. Ce fonctionnement est à l’origine même de l’intérêt des mémoires caches: lorsqu’une donnée est utilisée, celle-ci est copiée afin d’accélérer de futurs utilisations.
Pour les simulations qui suivent, on considèrera qu’aucune opération n’est effectuée dans la fonction func.
var.
Mesurez le temps d’accès mémoire du load (chargement) correspondant.
Attention: le cache L1I peut également engendrer des cache miss menant à des ralentissements.
Regarder seulement le temps d’exécution global peut donc ne pas être suffisant.var.
Mesurez le temps d’exécution du load (chargement) correspondant.Localité spatiale
Le concept de localité spatiale est l’observation que lorsque une zone mémoire est utilisée, il y a de plus grandes chances que les zones mémoires proches le soient également dans un futur proche. C’est le cas des instructions exécutées linéairement (sans redirection du flot d’exécution) mais aussi des données placées dans un même tableau.
Pour tenir compte de ce fonctionnement, les mémoires caches sont conçus pour manipuler des blocs de plusieurs octets de mémoire appelés ligne de cache. Ainsi, lorsqu’un accès est effectué sur un ou plusieurs octets d’une même ligne, c’est l’ensemble de la ligne qui est copiée dans la mémoire cache. De ce fait, les accès dans un futur proche aux autres octets de la ligne seront également accélérés.
Pour les simulations qui suivent, on considèrera qu’aucune opération n’est effectuée dans la fonction func.
line afin déduire la taille d’une ligne du cache L1D dans le processeur core_4.Aide supplémentaire (si nécessaire)
L’attribut __attribute__ ((aligned (8))) permet de contraindre l’alignement mémoire d’une variable.
Ainsi, avec cette directive, le compilateur va placer la variable associée à une adresse étant un multiple de 8.
Pour cela, il va si nécessaire laisser des espaces vides en mémoires.
Cette fonctionnalité peut être particulièrement utile pour s’assurer que toutes les données sont sur une même ligne de cache ou une même page mémoire.
line.
Déduisez le tag et l’index de la ligne de cache correspondante.
Aidez-vous des informations dans le chronogramme (partie L1D de GtkWave).L1D de GtkWave, expliquez l’évolution de l’état d’une ligne correspondante au moment d’un cache miss.Organisation interne
Afin de limiter la latence lors de la vérification des lignes, les mémoires caches sont généralement organisées en interne par ensemble ou sous-ensembles. À partir des bits d’index de l’adresse, l’ensemble correspondant est ensuite sélectionné statiquement: seuls les emplacements qu’il contient doivent être vérifiés.
cache pour qu’il occupe la taille du cache entier.
Écrivez une boucle écrivant la valeur i (l’index du tableau) dans chacune des cases du tableau.
Combien de cache hit / cache miss sont ainsi générés ?
Est-ce cohérent avec vos précédents résultats ?Politique de remplacement
Une fois tous les emplacements d’une mémoire cache occupés, celle-ci doit pouvoir continuer à s’adapter aux besoin des différents programmes exécutés. Le cache doit donc alors être capable de supprimer d’anciennes lignes pour les remplacer par des nouvelles. Au sein de chaque ensemble d’une même mémoire, le choix de la ligne à remplacer dépend de la politique de remplacement implémentée.
Une politique de remplacement est un algorithme implémenté dans le matériel permettant d’effectuer un choix de ligne. Il existe plusieurs types d’implémentations parmi lesquelles:
- Least-Recently Used (LRU) qui sélectionne la ligne ayant été utilisée le moins récemment. C’est une application directe du principe de localité temporelle.
- Pseudo Least-Recently Used (PLRU) qui vise à se rapprocher d’un fonctionnement en LRU en réduisant le coût matériel.
- First-In First-Out (FIFO) qui sélectionne la première ligne ayant été ramenée dans la mémoire cache.
replace afin de déduire la politique de remplacement utilisée dans le cache L1D du processeur core_4.Aide supplémentaire (si nécessaire)
On simplifiera le problème en considérant que la politique de remplacement utilisée est ici soit LRU (Least Recently Used), soit FIFO (First-In First-Out).
Ordre des accès
Lorsque l’on effectue de nombreux accès mémoires, les méooires caches peuvent s’avérer insuffisantes pour contenir toutes les données manipulées. Il peut alors être nécessaire de prendre en compte la répartition en mémoire pour limite le nombre de cache miss.
mat1[y][x] avec la valeur 1.
Comment sont réparties les cases de la matrice sur les différentes lignes de cache ?
Combien de cache hit/ cache miss obtenez-vous ?mat2[y][x] par la valeur y * x + x.mat3 = mat1 + mat2 en imbriquant le parcours des x dans la boucle parcourant les y.
Mesurez le temps d’exécution global.mat3 = mat1 + mat2 en imbriquant le parcours des y dans la boucle parcourant les x.
Mesurez le temps d’exécution global.Étude de la mémoire cache L2
Le processeur contient un deuxième niveau (L2) de cache L2 commun. En vous inspirant de ce qui a été fait auparavant, déduisez les informations suivantes :
- Le nombre d’ensembles,
- Le nombre de lignes par ensemble,
- La taille totale du niveau L2,
- S’il est unifié (instructions + données).